
Jan 2, 2026Luke
Caret NotebookLM: The Future of Sovereign AI and Open Source Through the Solar 100B Allegations
Through the technical discussion surrounding Upstage's Solar 100B model, we explore the path forward for true sovereign AI and the importance of open-source public verification from Caret's perspective as a trusted AI companion.
Recently, the Korean AI community has been buzzing with technical discussions surrounding Upstage's Solar 100B model. As claims emerged that the model was derived from a Chinese open-source model, the importance of technical verification has become more prominent than ever.

This debate extends beyond a single company's model, posing a crucial question to us all: what constitutes true 'Sovereign AI,' and why is a healthy alliance with the global open-source ecosystem essential? Upstage's promise of a transparent response and the community's voluntary participation have opened a forum for healthy technical debate, fostering the collective growth of the domestic AI ecosystem.
To delve deeper into this topic, we at Caret have produced two videos using the Caret Notebook LM.
- Overview:
- Discussion:
Both videos were created using our open-source NotebookLM to YouTube project. We will continue to share related news through the Caret blog.
Caret's Perspective: Toward a Trustworthy AI Companion
Of course, it's difficult to directly compare a company building massive models like Upstage with a startup like ours that is just taking its first steps. To be frank, it might even seem like we're just trying to jump on the bandwagon of this hot-button issue. 😅
However, as creators of an 'AI companion' and as developers who use AI daily, this discussion resonates with us on a different level. It serves as a prime example of how crucial 'trust' and 'transparency' are to the advancement of AI technology, especially Sovereign AI, and how a public verification process through the community can foster a healthy tech ecosystem.
This is precisely why we at Caret dream of creating a 'co-evolving AI companion' based on the stability-proven open-source Cline. For an AI to become a developer's closest colleague, it must, above all, be trustworthy. That trust can only be solidified through a transparent process of disclosing source code, evolving with the community, and undergoing continuous verification.
We hope this discussion transcends unproductive disputes and, like Upstage's commitment to public verification, becomes an opportunity for the entire domestic AI ecosystem to reaffirm the values of transparency and openness and grow together. As a member of the open-source community, Caret will also strive to create tools and a culture that contribute to a healthy technological ecosystem.
[Post-Broadcast Review] How 'Logs' Turned All Allegations into Proof
Through Upstage's technical verification broadcast, all previous allegations were substantiated with clear data and logs. You can watch the full broadcast at the original link.
As a developer, here’s a summary of the key evidence presented in the broadcast, explaining why it was decisive and how the initial criticisms stemmed from a technical misunderstanding.
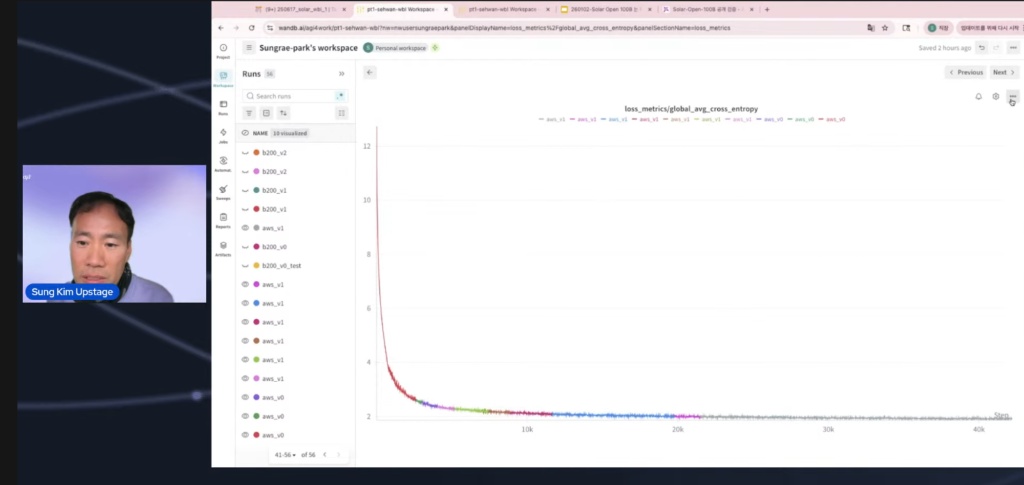
- Decisive Proof: WandB Training Log Charts Confirming 'From Scratch' The most powerful evidence was the 'WandB training log chart' that recorded and visualized the entire model training process. The publicly shared chart clearly showed a curve where the Loss value started at 12 from the very first checkpoint and then dropped sharply.
What this means: If they had fine-tuned by importing a checkpoint from a pre-trained model, the initial loss couldn't have been this high (it usually starts around 2-3).
The core of the controversy was the definition of 'From Scratch.' Since many were confused by this standard, the broadcast began by clarifying it. It was made clear that starting training from a blank slate inevitably results in a very high initial loss value.

As proof, they revealed a screenshot of the WandB dashboard that recorded the actual training process. The image below shows the initial Loss value starting very high, which is strong physical evidence that the model began learning from a blank slate.
- The "Similarity" Trap: Looking at Direction, Not Magnitude It was also demonstrated why 'Cosine Similarity,' the starting point of the allegations, was a flawed metric.
Limitation of the metric: Cosine similarity only considers the 'direction' of vectors. If the same architecture (blueprint) is used, the vector directions are bound to be similar due to the structural characteristics of the layers.
Actual comparison: When examining the weights element-wise, the scale and specific numerical values were completely different. It confirmed the fact that "just because they all point to the North Star doesn't mean they are the same flashlight."
(As a fun side note, the images below contain a snippet of Upstage's conversation at the time, like a little 'Easter egg'. 😅)


- Structural Differentiation: An 'Improvement,' Not a Copy
Structural features were also clearly explained, showing that it was not a simple duplicate.
 Differences from GPT-OSS 120B: The structure was reinforced by adding Shared Layers for stable training.
Differences from GPT-OSS 120B: The structure was reinforced by adding Shared Layers for stable training.
Differences from GLM: It was confirmed that independent engineering decisions and optimizations were made, such as boldly removing Dense Layers deemed to have little impact on performance.
Conclusion This clarification provided great credibility to the developer community because it was proven not with emotional appeals, but with data, logs, and architecture. In the end, it was a moment that re-affirmed the truth that "code doesn't lie."
More posts

Check out the release notes for Caret v0.4.4, featuring major new capabilities like image generation with Nanobanana Pro, support for Naver HyperClova X models, and adoption of the AAIF standard Agents.md in our first update of 2026.
